The idea behind Neon is to create a new serverless Postgres service with a modern cloud-native architecture. When building for the cloud it usually is a good idea to separate storage and compute. For operational databases such design was first introduced by AWS Aurora 1, followed by many others 2 3, however none of the implementations were open source and native to Postgres.
We wanted to make Neon the best platform to run Postgres on. As we started to figure out the details we needed to understand what exactly the architecture should look like for an OLTP cloud database. We also knew that we couldn’t deviate from Postgres. People choose Postgres for many reasons. It’s open source, feature-rich, and has a large ecosystem of extensions and tools. But increasingly, it’s simply the default choice. There are a lot of databases out there with different strengths and weaknesses, but unless you have a particular reason to pick something else, you should just go with Postgres. Therefore, we don’t want to compete with Postgres itself or maintain a fork. We understood that Neon would only work in the market if it doesn’t fork Postgres and gives users 100% compatibility with their apps written for Postgres.
So before we wrote a single line of code, we had some big upfront decisions to make on the architecture.
Separating storage and compute
The core idea of an Aurora-like architecture of separation of storage and compute is to replace the regular filesystem and local disk with a smart storage layer.
Separating compute and storage allows you to do things that are difficult or impossible to do otherwise:
- Run multiple compute instances without having multiple copies of the data.
- Perform a fast startup and shutdown of compute instances.
- Provide instant recovery for your database.
- Simplify operations, like backups and archiving, to be handled by the storage layer without affecting the application.
- Scale CPU and I/O resources independently.
The first major decision for us was if we should just use a SAN or an off-the-shelf distributed file system. You can certainly get some of these benefits from smart filesystems or SANs, and there are a lot of tools out there to manage these in a traditional installation. But having a smart storage system that knows more about the database system and the underlying infrastructure of the cloud provider makes the overall system simpler, and gives a better developer experience. We were aware of Delphix – a company that is built on the premise of providing dev and test environments for database products using zfs. If we took a similar approach due to the fact that we don’t control the filesystem tier, it would be hard to efficiently integrate it with the cloud and result in a clunky and expensive solution. We could still sell it to large enterprises, but we knew we could do better. So the first decision was made: no SANs, no third party filesystems. Let’s build our own storage from the first principles.
Storage Interface
We started to think about what the interface should be between compute and storage. Since we have many Postgres hackers on the team, we already knew how it works in vanilla Postgres. Postgres generates WAL (write ahead log) for all data modifications, and the WAL is written to disk. Each WAL record references one or more pages, and an operation and some payload to apply to them. In essence, each WAL record is a diff against the previous version of the page. As Postgres processes a WAL record it applies the operation encoded in the WAL record to the page cache, which will eventually write the page to disk. If a crash occurs before this happens, the page is reconstructed using the old version of the page and the WAL.
Postgres architecture gave us a hint of how to integrate our cloud native storage. We can make Postgres stream WAL to Neon storage over the network and similarly read pages from Neon storage using RPC calls. If we did that, Postgres changes would be minimal and we can even hope to push them upstream.
It was clear that we will need to have a consensus algorithm for persisting the WAL – the database is the log, it has to be incredibly robust. And it was also clear that we need to organize pages so that we can quickly return them when requested by Postgres. What was not clear was if we should have two services: one for WAL and one for serving pages or one that combines all of it. Aurora has one, SQL Server, which came later, has two. There was a decision to make.
Separating Page servers and the WAL service
One early decision was to separate the WAL and page service. The WAL service consists of multiple WAL safekeeper nodes that receive the WAL from Postgres, and run a consensus algorithm. The consensus algorithm ensures durability, even if one of the safekeeper nodes is down. It also ensures that only one Postgres instance is acting as the primary at any given time, avoiding split-brain problems. Pageservers store committed WAL and can reconstruct a page at any given point of WAL on request from the compute layer.
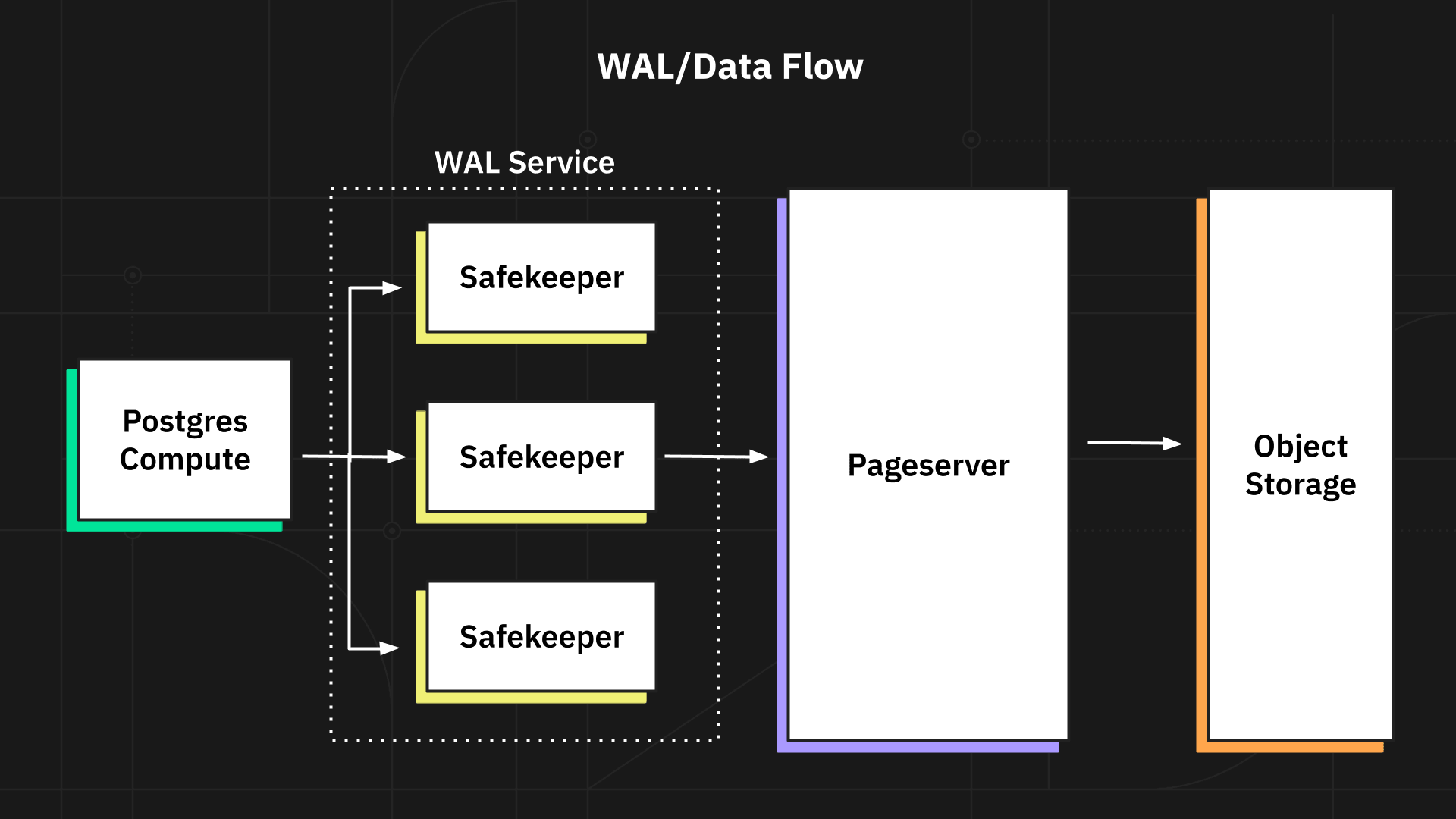
Separating the WAL service has several advantages:
- The WAL service and the page servers can be developed independently and in parallel.
- It is easier to reason about and verify the correctness of the consensus algorithm when it is a separate component.
- We can use hardware optimized for different purposes efficiently; the I/O pattern and workload of the safekeepers is very different from the page servers – one is append-only, and the other one is both read, write, and update.
Relationship between compute and pageservers
Does one compute only talk to one pageserver or should we spread out pages from one database across multiple pageservers? Also, does one pageserver only contain data for one or many databases? The latter question is a simple one. We need to build multi-tenancy to support a large number of small databases efficiently. So one pageserver can contain pages from many databases.
The former question is a trade-off between simplicity and availability. If we spread database pages across many pageservers, and especially if we cache the same page on multiple page servers, we can provide better availability in case a page server goes down. To get started, we implemented a simple solution with one pageserver, but will add a pageserver “sharding” feature later to support high availability and very large databases.
Treat historical data the same as recent data
The most straightforward model for the page servers would be to replay the WAL as it is received, to keep an up-to-date copy of the database – just like a Postgres replica. However, replicas connected to the storage system can lag behind the primary, and need to see older versions of pages. So at least you need some kind of a buffer to hold old page versions, in case a read replica requests them. But for how long? There’s no limitation on how far behind a read replica can lag.
Then we started to think about WAL archiving, backups and Point-in-Time Recovery (PITR). How are those things going to work in Neon? Do we need to build them as separate features or can we do better? Could the storage handle all of those?
PITR is a standard feature in most serious OLTP installations. The canonical use case for PITR is that you accidentally drop a table, and want to restore the database to the state just before that. You don’t do PITR often, but you want to have the capability. To allow PITR, you need to retain all old page versions in some form, as far back as you want to allow PITR. Traditionally, that’s done by taking daily or weekly backups and archiving all the WAL.
You don’t do PITR often, because it has traditionally been a very expensive operation. You start from the last backup and replay all the archived WAL to get to the desired point in time. This can take hours. And if you pick the wrong point to recover to, you have to start all over again.
What if PITR was a quick and computationally cheap operation? If you don’t know the exact point to recover to, that’s OK; you can do PITR as many times as you need to. You could use it for many things that are not feasible otherwise. For example, if you want to run an ad hoc analytical query against an OLTP database, you could do that against a PITR copy instead, without affecting the primary.
If you have a storage system that keeps all the old page versions, such operations become cheap. You can query against an older point in time just the same as the latest version.
We decided to embrace the idea of keeping old page versions, and build the storage system so that it can do that efficiently. It replaces the traditional backups and the WAL archive, and makes all of the history instantly accessible. The immediate question is “But at what cost”? If you have a PITR horizon of several weeks or months, that can be a lot of old data, even for a small database. We needed a way to store the old and cold data efficiently and the solution was to move cold and old data to cloud object storage such as S3.
Leverage cloud object storage
The most efficient I/O pattern is to write incoming data sequentially and avoid random updates of old data. In Neon, incoming WAL is processed as it arrives, and indexed and buffered in memory. When the buffer fills up, it is written to a new file. Files are never modified in place. In the background, old data is reorganized by merging and deleting old files, to keep read latency in check and to garbage collect old page versions that are no longer needed for PITR. This design was inspired by Log-Structured Merge-trees.
This system, based on immutable files, has a few important benefits. Firstly, it makes compression easy. You can compress one file at a time, without having to worry about updating parts of the file later. Secondly, it makes it easy to scale the storage, and swap in and out parts of the database as needed. You can move a file to cold storage, and fetch it back if it’s needed again.
Neon utilizes cloud object storage to make the storage cost-efficient and robust. By relying on object storage, we don’t necessarily need multiple copies of data in the page servers, and we can utilize fast but less reliable local SSDs. Neon offloads cold parts of the database to object storage, and can bring it back online when needed. In a sense, the page servers are just a cache of what’s stored in the object storage, to allow fast random access to it. Object storage provides for the long-term durability of the data, and allows easy sharding and scaling of the storage system.
One year later
We built a modern, cloud-native architecture that separates storage from compute to provide an excellent Postgres experience. Different decisions would have made some things easier and others harder, but so far, we haven’t regretted any of these choices. The immutable file format made it straightforward to support branching, for example, and we have been able to develop the page server and safekeeper parts fairly independently, just like we thought. You can get early access to our service and experience the benefits directly.
1. A. Verbitski et al., “Amazon Aurora,” Proceedings of the 2017 ACM International Conference on Management of Data. ACM, May 09, 2017 [Online]. Available: https://dx.doi.org/10.1145/3035918.3056101↩
2. P. Antonopoulos et al., “Socrates,” Proceedings of the 2019 International Conference on Management of Data. ACM, Jun. 25, 2019 [Online]. Available: https://www.microsoft.com/en-us/research/uploads/prod/2019/05/socrates.pdf↩
3. W. Cao et al., “PolarDB Serverless,” Proceedings of the 2021 International Conference on Management of Data. ACM, Jun. 09, 2021 [Online]. Available: http://dx.doi.org/10.1145/3448016.3457560↩
📚 Keep reading
- A deep dive into our storage engine: Neon’s custom-built storage is the core of the platform—get details into how its built.
- How we scale an open-source, multi-tenant storage engine for Postgres written in Rust: keep learning about how we implemented sharding in our storage to allow Neon to host larger datasets and I/O.
- 1 year of autoscaling Postgres: a review of our autoscaling design. Neon can autoscale your Postgres instance without dropping connections or interrupting your queries, avoiding the need for overprovisioning or resizing manually.