The AI wars have begun. Not the one where the machines enslave us and use our body heat to power their compute–that’s at least 18 months off. 🙂 No, this AI war is between the tech giants and between closed, proprietary models and open source.
In one corner, we have OpenAI, supported by Microsoft, building out the strongest closed models with their GPT line. These models have set the benchmark for performance in natural language processing tasks, demonstrating remarkable capabilities in understanding and generating human-like text across a wide range of applications.
In the other, we have Zuck and his Llamas. And the Llamas are growing strong. The latest Llama model, Llama 3.1, represents a significant leap forward in open-source AI technology, offering comparable performance to the top proprietary models while providing the freedom to study, modify, and deploy the model without the restrictions and costs of closed-source alternatives.
So that’s what we’re going to do here. We will use the latest and greatest Meta has to offer to build out a RAG application that allows us to augment the model’s response with our own specific knowledge.
But first, we have to answer this question:
What is RAG?
RAG, or Retrieval-Augmented Generation, is an AI technique that combines the power of large language models (LLMs) with external knowledge retrieval. The idea is to fix one of LLMs’ key limitations: their inability to access or update their knowledge after training.
In a RAG system, when a query is received, it first goes through a retrieval step. This step searches a knowledge base to find relevant information. Once relevant information is retrieved, it’s fed into the LLM along with the original query. This allows the model to generate responses based not only on its pre-trained knowledge but also on the most up-to-date and relevant information from the external knowledge base.
There are a few ways to do this, but the most common current technique is using embeddings. Embeddings are a mathematical representation of the text in the knowledge base. Using a specific embedding model, you convert text into a dense vector representation (called an embedding).
When the text is represented as this vector, performing similarity searches on these numbers is much easier. So the basic process goes:
- You have a lot of text or documents. After some preprocessing (splitting it and cleaning it up), you create an embedding for each element of the text.
- You store these in a vector database–a specialized (or not 😉) database that efficiently stores these long embeddings.
- When a user makes a query, you then run that query through the embedding model to create its own embedding.
- You then search through your database looking for similar embeddings.
- You return the text associated with the N similar embeddings from the database, which are then passed to the LLM along with the original query.
- The LLM uses the query and the returned text to formulate a more specific, relevant, and up-to-date answer for the user.
You can see the applications. You can add your documentation to a vector database and build a model that allows users to pull the exact way to use your API. You can add all your past customer service interactions to a vector database and build a model that understands the biggest problems for your customers. You can add all your company’s internal knowledge base articles to a vector database and build a model that provides accurate and up-to-date information to employees across different departments.
RAG is extremely useful. And the underpinning technology of RAG is the vector database. Many specific vector database tools are available for this application, but as the saying goes, “Just Use Postgres.”
Creating a vector database using Postgres is astonishingly easy, and we’ll do that here.
Building our AI app
OK, so what are we going to build? We’re going to create a fairly simple application that peps us up with inspirational quotes. We’ll create these quotes ourselves and store them for retrieval.
The tech stack
Here’s what we’re going to use:
- Llama 3.1 for our model. Llama 3.1 is Meta’s latest open-source large language model, providing state-of-the-art performance for natural language AI tasks without the restrictions of proprietary models.
- Neon for our vector database. You probably know this, but Neon is a serverless Postgres database that offers vector operations via pgvector. Its serverless compute and storage scaling makes it ideal for storing and querying our embeddings efficiently.
- OctoAI to stitch everything together. OctoAI is a platform that simplifies the deployment and management of open-source AI models, allowing us to easily integrate Llama 3.1 and our Neon database into an application.
Creating a vector database in Neon
Neon has a Free plan: to start, create an account here and follow these instructions to connect to your database.
Once you’re connected, to turn Neon into a vector database just takes three words:
CREATE EXTENSION vector;
That’s it. Neon ships with pgvector, a Postgres extension that enables efficient storage and similarity search of embeddings. We can then create a quotes table that includes embeddings alongside the rest of our data:
CREATE TABLE quotes (
id BIGSERIAL PRIMARY KEY,
quote text,
author text,
embedding VECTOR(1024)
);So this table has four columns:
id: A BIGSERIAL PRIMARY KEY serving as the primary identifier for each quote.quote: A text column that stores the actual text of the inspirational quote.author: A text column that stores the name of the person who said or wrote the quote.embedding: A VECTOR(1024) column that stores the 1024-dimensional vector representation of the quote generated by an embedding model.
This vector allows for efficient similarity searches in the vector space later. Why 1024? Well, because that is the length of the output vector from the embedding model we’re going to use. If you were using the OpenAI embedding model, this number would be up to 3072. This is a good place to be cautious. The longer the embedding, the more storage it will use and the higher the cost.
Now we have our vector database (yes, that was all you had to do). Let’s populate it.
Creating embeddings
In this case, we’ve created a few fake quotes and stored them in a CSV. We’ve done this purely to show that the model is pulling from our RAG data rather than grabbing the quotes from somewhere else. We can then do steps 1-3 from above.
Luckily, as we’ve faked the data, we don’t need to do any cleanup, and we can get straight into creating and storing our embeddings. Here’s the Python code:
import requests
import os
import csv
from psycopg2 import pool
from dotenv import load_dotenv
import time
# Load .env file
load_dotenv()
def load_csv(filename):
quotes, authors = [], []
with open(filename, 'r') as file:
reader = csv.reader(file)
for row in reader:
if row:
quotes.append(row[0])
authors.append(row[1])
return quotes, authors
def get_embeddings(quotes):
embeddings = []
url = "https://text.octoai.run/v1/embeddings"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.getenv('OCTO_API_TOKEN')}"
}
for quote in quotes:
data = {
"input": quote,
"model": "thenlper/gte-large"
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
response_json = response.json()
embeddings.append(response_json['data'][0]['embedding'])
else:
print(f"Request failed with status code {response.status_code}")
# Optional: Add delay to avoid hitting the rate limit
time.sleep(1)
return embeddings
def insert_into_db(quotes, authors, embeddings):
connection_string = os.getenv('DATABASE_URL')
connection_pool = pool.SimpleConnectionPool(1, 10, connection_string)
if connection_pool:
print("Connection pool created successfully")
try:
conn = connection_pool.getconn()
cur = conn.cursor()
for quote, author, embedding in zip(quotes, authors, embeddings):
cur.execute(
"INSERT INTO quotes (quotes, author, embedding) VALUES (%s, %s, %s)",
(quote, author, embedding)
)
conn.commit()
cur.close()
finally:
connection_pool.putconn(conn)
connection_pool.closeall()
def main():
quotes, authors = load_csv('fake_quote.csv')
embeddings = get_embeddings(quotes)
if len(quotes) != len(embeddings):
print("Mismatch between number of quotes and embeddings")
return
insert_into_db(quotes, authors, embeddings)
if __name__ == "__main__":
main()
What do each of these functions do?
load_csv(filename): We’re parsing our CSV of quotes and returning the list of quotes and authors.get_embeddings(quotes): This is the heart of the code. We generate an embedding for each quote using the “helper/gte-large” model via the OctoAI API and return this list of embeddings.insert_into_db(quotes, authors, embeddings): Now we can add everything to Neon. We utilize a connection pool for efficient database connections and execute an SQL INSERT statement for each quote-author-embedding trio, committing the transaction at the end. It ensures proper closure of database connections and the connection pool.
With that done, we can see our data in the Neon tables page:
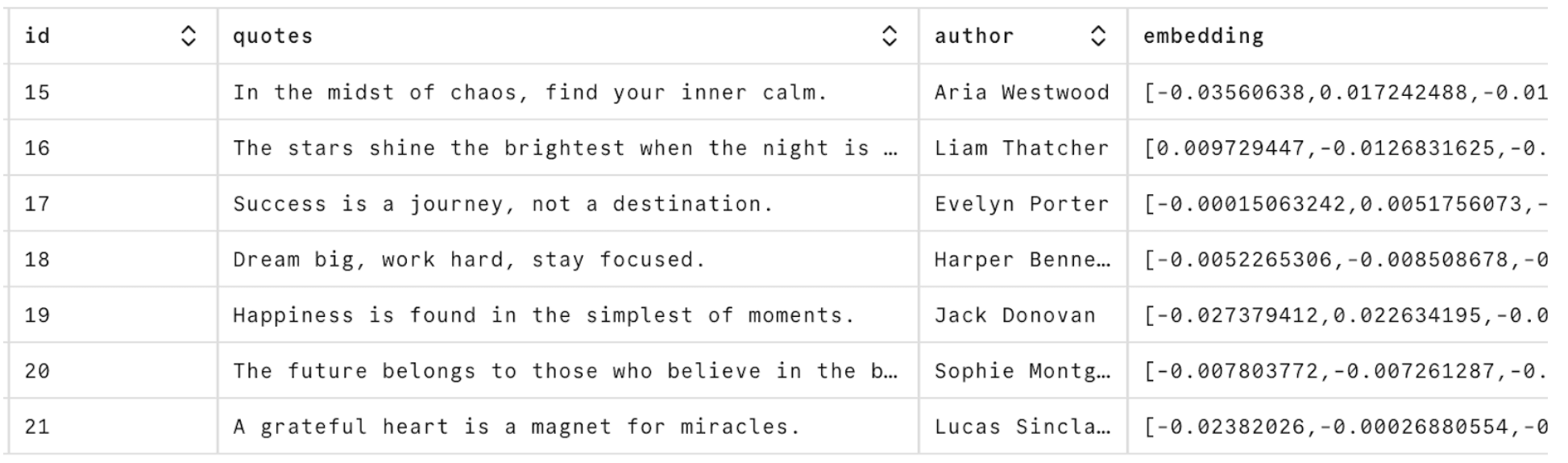
This is also a good way to see what embeddings are–just long lists of numbers. These embeddings underpin everything within the AI revolution. It’s all about matching these numbers.
Now we can start using this data.
Building a RAG model with Llama 3.1
Now we’re at the business end. Let’s start with the code, and then we’ll walk through it:
import requests
import sys
import os
import json
from psycopg2 import pool
from dotenv import load_dotenv
from octoai.text_gen import ChatMessage
from octoai.client import OctoAI
# Load .env file
load_dotenv()
def get_input_embedding(text):
url = "https://text.octoai.run/v1/embeddings"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.getenv('OCTO_API_TOKEN')}"
}
data = {
"input": text,
"model": "thenlper/gte-large"
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
response_json = response.json()
embedding_vector = response_json['data'][0]['embedding']
return embedding_vector
else:
print(f"Request failed with status code {response.status_code}")
return None
def get_quotes(input_embedding):
# Get the connection string from the environment variable
connection_string = os.getenv('DATABASE_URL')
# Create a connection pool
connection_pool = pool.SimpleConnectionPool(
1, # Minimum number of connections in the pool
10, # Maximum number of connections in the pool
connection_string
)
# Check if the pool was created successfully
if connection_pool:
print("Connection pool created successfully")
try:
# Get a connection from the pool
conn = connection_pool.getconn()
# Create a cursor object
cur = conn.cursor()
cur.execute(f"SELECT * FROM quotes ORDER BY embedding <-> '{input_embedding}' LIMIT 2;")
# Fetch the results
quotes = cur.fetchall()
# Extract and print the quote text and author name
retrieved_quotes = []
for item in quotes:
quote_text = item[1]
author_name = item[2]
retrieved_quotes.append(f'"{quote_text}" - {author_name}')
# Commit the transaction
conn.commit()
# Close the cursor
cur.close()
return retrieved_quotes
finally:
# Return the connection to the pool
connection_pool.putconn(conn)
# Close the connection pool
connection_pool.closeall()
def generate_response(user_input, retrieved_quotes):
# Construct the system prompt with retrieved quotes
system_prompt = (
"You are helping people get motivated. Here are some quotes related to your input:\n" +
"\n".join(retrieved_quotes) +
"\nPlease provide a response related to the input and consider the above quotes."
)
client = OctoAI(
api_key=os.getenv('OCTO_API_TOKEN'),
)
completion = client.text_gen.create_chat_completion(
model="meta-llama-3.1-405b-instruct",
messages=[
ChatMessage(
role="system",
content=system_prompt,
),
ChatMessage(role="user", content=user_input),
],
max_tokens=150,
)
message_content = completion.choices[0].message.content
# Print the message content
print(message_content)
def main():
if len(sys.argv) < 2:
print("Usage: python input.py 'Your text string goes here'")
return
user_input = sys.argv[1]
# Get the embedding vector for the input text
embedding_vector = get_input_embedding(user_input)
if embedding_vector:
# Get quotes similar to the input text
retrieved_quotes = get_quotes(embedding_vector)
if retrieved_quotes:
# Generate and print the response
generate_response(user_input, retrieved_quotes)
else:
print("No quotes retrieved from the database.")
else:
print("Failed to get embedding vector")
if __name__ == "__main__":
main()
This starts with the user input. We’re just using the command line here, but you can imagine this input coming from an app or other frontend. This is a motivational app, so let’s ask it about some dreams:
python input.py 'I want to know about dreams'
That text is passed to get_input_embedding. In this function, we’re doing exactly what we did above and creating an embedding for this string. Ultimately, we want a 1024-length vector we can check against the stored 1024-length vectors in our Neon vector database.
This embedding_vector is then passed to get_quotes. This sets up a connection to Neon again, but instead of inserting elements, this time it runs this SQL query:
SELECT * FROM quotes ORDER BY embedding <=> '{input_embedding}' LIMIT 2;
Where input_embedding is the embedding of our user input. This query performs a similarity search in the vector space of our stored quotes. The ‘<=>’ operator calculates the cosine distance between the input embedding and each embedding in the database. By ordering the results based on this distance and limiting them to 2, we retrieve the two most similar quotes to our input. In this case, this function will output:
Quote: Dream big, work hard, stay focused.
Author: Harper Bennett
Quote: The future belongs to those who believe in the beauty of their dreams.
Author: Sophie MontgomeryYou can see the ‘similarity,’ with both of these quotes talking about dreams. Now, RAG’s second magic trick is adding these quotes to the context of our larger model. Let’s just show this code again and then step through it:
def generate_response(user_input, retrieved_quotes):
# Construct the system prompt with retrieved quotes
system_prompt = (
"You are helping people get motivated. Here are some quotes related to your input:\n" +
"\n".join(retrieved_quotes) +
"\nPlease provide a response related to the input and consider the above quotes."
)
client = OctoAI(
api_key=os.getenv('OCTO_API_TOKEN'),
)
completion = client.text_gen.create_chat_completion(
model="meta-llama-3.1-405b-instruct",
messages=[
ChatMessage(
role="system",
content=system_prompt,
),
ChatMessage(role="user", content=user_input),
],
max_tokens=150,
)
message_content = completion.choices[0].message.content
# Print the message content
print(message_content)The function takes two parameters: the user’s input and the quotes we retrieved from our vector database. It then uses those to construct the system prompt, using the retrieved quotes as context.
We then initialize the OctoAI client. This is where we’re calling the Llama 3.1 model through OctoAI. We’re using the chat completion endpoint, providing our constructed system prompt and the user’s input as messages. We’re limiting the response to 150 tokens.
Finally, we extract and print the generated response from the model’s output. This is what we get for the above input:
Dreams! The spark that ignites the fire of motivation within us. As Sophie Montgomery so eloquently put it, "The future belongs to those who believe in the beauty of their dreams." This quote reminds us that our dreams are the foundation upon which we build our futures. They give us direction, purpose, and a sense of what's possible.
But, as Harper Bennett added, it's not just about having dreams; it's about taking action towards making them a reality. "Dream big, work hard, stay focused." This quote highlights the importance of putting in the effort required to bring our dreams to life. It's not just about wishing for something to happen, but about creating a plan, working towards it, and staying committedThis embodies the core of our RAG system: it takes the context we’ve retrieved from our vector database (the quotes) and uses it to inform the language model’s response to the user’s input. We get those quotes back in our response, adding more relevancy to the model’s output.
We’ve created a RAG model with Llama 3.1 and Neon. What is the cost of all the AI calls here?
One cent. And that’s with all the tests while building.
Your AI apps have a home: Postgres
Hopefully, you’ve learned three things with this post:
- RAG is extremely powerful. This is just a toy example, but imagine having thousands of documents in a vector database and being able to add all that knowledge to a regular LLM. It can make the applications you build much more relevant to your users.
- Open-source models are up for the fight. We’re obviously barely scratching the surface of what Llama 3.1 can do, but the benchmarks put it up against OpenAI, Claude, and Cohere, and for a fraction of the cost.
- Postgres is a vector database. Like with Llama 3.1, we’ve barely started exploring the possibilities of Postgres and vectors. You can learn more about optimizing Neon for embeddings, and this is a great read on how Postgres compares to specialized Vector databases.
If you are using Neon, you already have a vector database. If you aren’t, sign up for free and start building your AI apps.