Read replicas
Maximize scalability and more with read replicas
Neon read replicas are independent computes designed to perform read operations on the same data as your primary read-write compute. Neon's read replicas do not replicate data across database instances. Instead, read requests are directed to a single source — a capability made possible by Neon's architecture, which separates storage and compute. The following diagram shows how your primary compute and read replicas send read requests to the same Neon Pageserver.
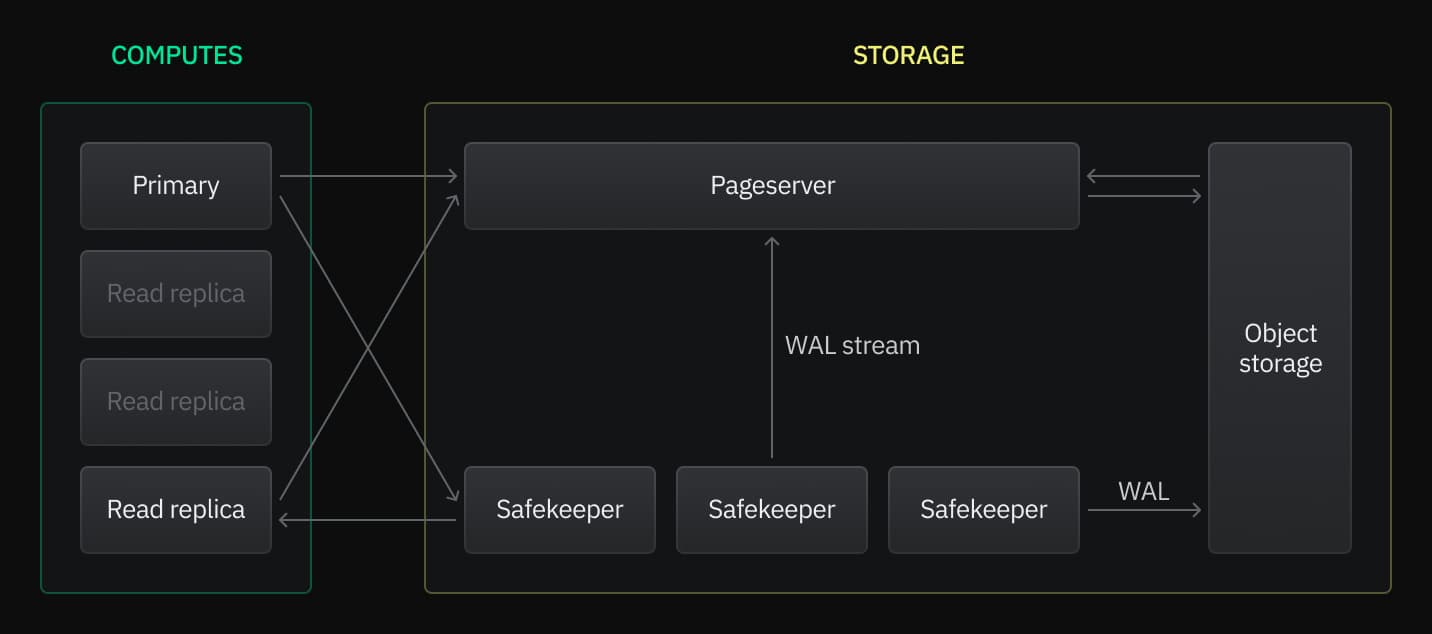
In data replication terms, Neon read replicas are asynchronous, which means they are eventually consistent. As updates are made by your primary compute, Safekeepers store the data changes durably until they are processed by Pageservers. At the same time, Safekeepers keep read replica computes up to date with the latest changes to maintain data consistency.
Neon supports creating read replicas in the same region as your database. Cross-region read replicas are currently not supported.
You can instantly create one or more read replicas for any branch in your Neon project and configure the amount of vCPU and memory allocated to each. Read replicas also support Neon's Autoscaling and Autosuspend features, providing you with control over the compute resources used by your read replicas.
Use cases
Neon's read replicas have a number of potential applications:
- Increase throughput: By distributing read requests among multiple read replicas, you can achieve higher throughput for both read-write and read-only workloads.
- Workload offloading: Assign reporting or analytical workloads to a read replica to prevent any impact on the performance of read-write application workloads.
- Access control: Provide read-only data access to certain users or applications that do not need write access.
- Resource customization: Configure different CPU and memory resources for each read replica to cater to the specific needs of different users and applications.
Advantages
Advantages of Neon's read replica feature include the following:
- Efficient storage: With read replicas reading from the same source as your primary read-write compute, no additional storage is required to create a read replica. Data is neither duplicated nor replicated, which means zero additional storage cost.
- Data consistency: Your primary read-write compute and read replicas read data from a single source, ensuring a high degree of data consistency.
- Scalability: With no data replication required, you can create read replicas almost instantly, providing fast and seamless scalability. You can also scale read replica compute resources the same way you scale your primary read-write compute resources.
- Cost effectiveness: By removing the need for additional storage and data replication, costs associated with storage and data transfer are avoided. Neon's read replicas also benefit from Neon's Autoscaling and Autosuspend features, which enable efficient management of compute resources.
- Instant availability. With an architecture that separates storage and compute, you can allow read replicas to scale to zero when not in use without introducing lag. When a read replica starts up, it is up to date with your primary read-write compute almost instantly.
Get started with read replicas
The first step to leveraging Neon's read replica feature is to sign up for a paid plan. After subscribing, you will be able to create and configure read replicas. To get started, refer to the Working with read replicas guide.
Last updated on